 As children, we were told by adults to take smaller bites when eating. We didn’t always understand the risk of choking that they saw, but ultimately it was easier and safer to chew those smaller bites. In some cases, taking smaller bites made the difference in finishing more of the meal. But have we translated that lesson to other things in our lives?
As children, we were told by adults to take smaller bites when eating. We didn’t always understand the risk of choking that they saw, but ultimately it was easier and safer to chew those smaller bites. In some cases, taking smaller bites made the difference in finishing more of the meal. But have we translated that lesson to other things in our lives?
Often we try to tackle things that are too big to sufficiently understand, estimate, or complete in a reasonable amount of time and we suffer for it. We don’t always see the risks that hide in more complex items and thus don’t feel compelled to break them down. Other times we fail to break things down due to unknowns, ignorance, uncertainty, pride, optimism, or even laziness.
Variation in Software
Delivering software products is a constant struggle with a variation of size and complexity. It’s everywhere, from the size of user stories to tasks to code changes to releases. It is present from the moment someone has an idea to the moment software is deployed. We strive to understand, simplify, prioritize and execute on different types of things that are difficult to digest. The more variation we see, the more we struggle with staying consistent and predictable.
Because of this variation, we need to be good at breaking things down to more manageable sizes. This need is so pervasive, I propose it be viewed as a fundamental skill in software. I don’t think most teams recognize this and certainly don’t develop the skill. Many people on Agile teams exposed to concepts like Story decomposition don’t often realize how often they need to apply similar practices in so many other ways.
Why Decomposition Matters
My example of eating small bites was simplistic. In developing software, there is a lot more to gain but it is still ultimately about reducing risk and making tasks easier.
Progress
According to The Progress Principle, a strong key to people remaining happy, engaged, motivated, and creative is making regular progress on meaningful work. Not surprisingly, we want to get things done, but we also want to feel a sense of pride and accomplishment.
Of course, stakeholders and other parties are interested in seeing progress from those they depend on. When we are able to make more regular progress toward goals, we provide better measurements and visibility for ourselves and others to know how we are doing.
It should be no surprise that smaller items enable quicker progress toward goals if done right. We certainly need to take care to avoid dependencies and wait time. Smaller, more independent goals allow more frequent progress and all the benefits that come with it.
Collaboration
As we have more people working on something, is it easier to put them all on a larger, more monolithic task or divide and conquer? Usually, we prefer to divide and conquer. Yet how we divide is important as well because dependencies and other kinds of blocking issues create wait time and frustration.
Decomposition can be one of the easier ways to get additional people involved with helping accomplish a larger goal. By breaking up work into more isolated items to be done in parallel, we are increasing the ability to swarm on a problem.
Complexity

Complexity is one of the greatest challenges in software development. With more interactions, operations, and behavior,s we are more likely to have edge cases and exposure to risk when anything changes. Large goals are easier places for complexity to hide. The larger the task is when we try to accomplish it, the more details we have to discover, understand, validate, and implement.
Focusing on smaller units of work can be a helpful constraint we place on ourselves. Why add our own constraints? When we constrain ourselves to work on a small portion of a larger task we are trying to limit the complexity that prevents us from accomplishing something. We want to avoid a downward spiral of “what if?” and “we are going to need” scenarios that, while important, can slow the task at hand and lead to overthinking and overdesigning and accumulating work we may never need. We are trying to avoid Analysis Paralysis.
Control
By looking at Kanban systems we can see wide variations in size can impact lead times. If we can be more consistent with the size of items flowing through a system then we will have more consistent throughput and cycle times. By breaking down work items more frequently into items of similar size cycle times become more stable and the average size (due to whatever size variation remains) becomes more useful for forecasting due to the law of large numbers.
Clarity
It isn’t a coincidence that Break It Down is also a slang phrase appearing in music and pop culture that also relates to our goals. Urban Dictionary defines “Break It Down” to mean: To explain at length, clearly, and indisputably. By looking at the pieces of a larger whole individually and in more details we can often gain more clarity and understanding of the bigger picture than if we had never spent the extra effort.
Summary
Software Development is a continual exercise in dealing with variation of size and complexity. From early feature ideas, to low-level code changes we have work that can be difficult to understand, manage, and predict, especially when it is large. Decomposition helps us make this work more manageable.
So, we need to remember to Break It Down. It is all about decomposition. And in software, decomposition is everywhere, yet so many struggle with recognizing the need and applying it well. I believe decomposition should be considered one of the most fundamental and critical skills in software development. Getting better at it takes a combination of discipline, practice, and learning but can pay off immensely.
To be effective, even this post required decomposition. We are going to continue with a series of posts exploring many of the individual types of variation in software and how lean/agile teams cope with these different situations.
 When you hear the term “extreme programming”, what do you think of? Coding while skydiving at 15,000 feet? Bug-fixing while scaling the north face of Kilimanjaro? Refactoring while swimming with sharks at the Great Barrier Reef?
When you hear the term “extreme programming”, what do you think of? Coding while skydiving at 15,000 feet? Bug-fixing while scaling the north face of Kilimanjaro? Refactoring while swimming with sharks at the Great Barrier Reef?
 I struggled with a number of potential topics for this blog before settling on this one. I understand this isn’t a flashy topic like a comparison of JavaScript MVC frameworks or centralized logging solutions; however, I’ve been working on-and-off with legacy applications throughout my career and have come to truly realize the constrictive nature of coupling logic. Avoiding coupled applications can save your sanity and possibly your business as well. In this post, I will discuss coupling in software applications, strategies for avoiding it and a plan to refactor a legacy application into a decoupled one to help your organization get more value from its product.
I struggled with a number of potential topics for this blog before settling on this one. I understand this isn’t a flashy topic like a comparison of JavaScript MVC frameworks or centralized logging solutions; however, I’ve been working on-and-off with legacy applications throughout my career and have come to truly realize the constrictive nature of coupling logic. Avoiding coupled applications can save your sanity and possibly your business as well. In this post, I will discuss coupling in software applications, strategies for avoiding it and a plan to refactor a legacy application into a decoupled one to help your organization get more value from its product. In the past, developers either had only the choice between multiple machines or sharing development environments. In the first instance, this is an expensive solution and in the second, lots of developers sharing a single environment leads to contention issues. To further exacerbate this problem, the trend is towards application deployments that involve multiple servers.
In the past, developers either had only the choice between multiple machines or sharing development environments. In the first instance, this is an expensive solution and in the second, lots of developers sharing a single environment leads to contention issues. To further exacerbate this problem, the trend is towards application deployments that involve multiple servers.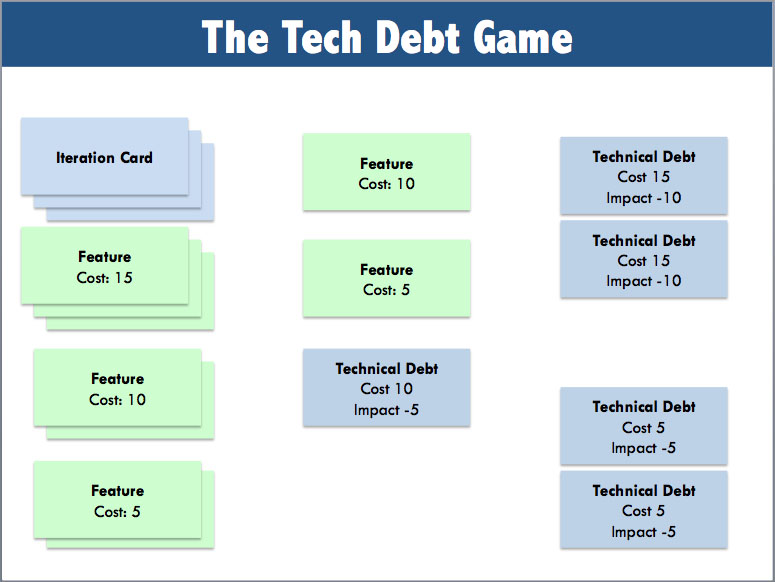
 Behavior Driven Development is the process of writing high-level scenarios verifying a User Story meets the Acceptance Criteria and the expectations of the stakeholders. The automation behind the scenarios is written to initially fail and then pass once the User Story development is complete.
Behavior Driven Development is the process of writing high-level scenarios verifying a User Story meets the Acceptance Criteria and the expectations of the stakeholders. The automation behind the scenarios is written to initially fail and then pass once the User Story development is complete. In the
In the  Agile software practitioners focus a lot of attention on people, communication, collaboration, and strong values. In many environments, these are unquestionably the best opportunities for improvement. Inevitably, though, all software development teams reach a point where their greatest opportunity for improving the way they implement and deliver a product are of a technical nature. There is no single standard set of universal technical practices, and Best Practices really need to be thought out in the context in which they would be used. Each team should look at what is most appropriate for their context.
Agile software practitioners focus a lot of attention on people, communication, collaboration, and strong values. In many environments, these are unquestionably the best opportunities for improvement. Inevitably, though, all software development teams reach a point where their greatest opportunity for improving the way they implement and deliver a product are of a technical nature. There is no single standard set of universal technical practices, and Best Practices really need to be thought out in the context in which they would be used. Each team should look at what is most appropriate for their context. The same TDD workflow that is most often applied to Unit Testing can be applied to different levels of tests. The most common TDD related testing activities are:
The same TDD workflow that is most often applied to Unit Testing can be applied to different levels of tests. The most common TDD related testing activities are: Continuous Delivery is in many ways an evolution or extension of
Continuous Delivery is in many ways an evolution or extension of  Agile Teams are always looking for frequent feedback and knowledge sharing and achieving both at the same time is a big win. By increasing the number of eyes that see and understand any given part of a code base, design, architecture, infrastructure, etc., we apply more knowledge, perspective, and experience to a solution and increase the number of people effectively working in that area.
Agile Teams are always looking for frequent feedback and knowledge sharing and achieving both at the same time is a big win. By increasing the number of eyes that see and understand any given part of a code base, design, architecture, infrastructure, etc., we apply more knowledge, perspective, and experience to a solution and increase the number of people effectively working in that area. Last week some of our team attended several DevOps Austin related events. We had a great time learning and interacting with other technologists attending both
Last week some of our team attended several DevOps Austin related events. We had a great time learning and interacting with other technologists attending both  This edition of the annual DevOps Days event in Austin (which also takes place in other cities each year) was declared the biggest. There were great discussions, Ignite talks, and
This edition of the annual DevOps Days event in Austin (which also takes place in other cities each year) was declared the biggest. There were great discussions, Ignite talks, and